# !pip install xxx -i http://pypi.douban.com/simple --trusted-host pypi.douban.comxxxxxxxxxximport requestsimport randomimport timeimport ioimport os# 导入pdfplumberimport pdfplumberimport pandas as pdimport rexxxxxxxxxxdef pdf2df(path): '''读取pdf并将其转换为df''' pdf = pdfplumber.open(path) df_list = [] pdf_page_num = len(pdf.pages) #pdf的页数 for i in range(pdf_page_num): p = pdf.pages[i] table = p.extract_table() #转成表格list df = pd.DataFrame(table[1:],columns=table[0]) #转成df df = df.fillna(method='pad') df_list.append(df) res = pd.concat(df_list) return resxxxxxxxxxxpath = r'证监会2021年3季度上市公司行业分类结果标准.pdf'zjh_industry_df = pdf2df(path) #证监会行业分类结果zjh_industry_df
x.dataframe tbody tr th {vertical-align: top;}.dataframe thead th {text-align: right;}
| 门类名称及代码 | 行业大类代码 | 行业大类名称 | 上市公司代码 | 上市公司简称 | |
|---|---|---|---|---|---|
| 0 | 农、林、牧、渔业\n(A) | 01 | 农业 | 000998 | 隆平高科 |
| 1 | 农、林、牧、渔业\n(A) | 01 | 农业 | 002041 | 登海种业 |
| 2 | 农、林、牧、渔业\n(A) | 01 | 农业 | 002772 | 众兴菌业 |
| 3 | 农、林、牧、渔业\n(A) | 01 | 农业 | 300087 | 荃银高科 |
| 4 | 农、林、牧、渔业\n(A) | 01 | 农业 | 300189 | 神农科技 |
| ... | ... | ... | ... | ... | ... |
| 37 | 综合(S) | 90 | 综合 | 600620 | 天宸股份 |
| 38 | 综合(S) | 90 | 综合 | 600673 | 东阳光 |
| 39 | 综合(S) | 90 | 综合 | 600766 | *ST园城 |
| 40 | 综合(S) | 90 | 综合 | 600770 | 综艺股份 |
| 41 | 综合(S) | 90 | 综合 | 600805 | 悦达投资 |
4492 rows × 5 columns
xxxxxxxxxx#所选行业为“文化艺术业”,行业大类代码为87df_ind = zjh_industry_df.loc[zjh_industry_df['行业大类代码'] == '87', :] #根据行业大类代码筛选出行业ind_stk_code= df_ind['上市公司代码'].tolist() #保存公司代码ind_stk_name = df_ind['上市公司简称'].tolist() #保存公司名称ind_stk_dict = dict(zip(ind_stk_name,ind_stk_code))ind_stk_dict
xxxxxxxxxx{'*ST当代': '000673','视觉中国': '000681','美盛文化': '002699','宋城演艺': '300144','芒果超媒': '300413','锋尚文化': '300860','祥源文化': '600576','风语筑': '603466'}
xxxxxxxxxxdef get_headers(): '''随机更换headers中的User-agent''' User_Agent = [ "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)", "Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)", "Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)", "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)", "Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6", "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1", "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0" ] headers = { 'Accept': 'application/json, text/javascript, */*; q=0.01', "Content-Type": "application/x-www-form-urlencoded; charset=UTF-8", "Accept-Encoding": "gzip, deflate", "Accept-Language": "zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7,zh-HK;q=0.6,zh-TW;q=0.5", 'Host': 'www.cninfo.com.cn', 'Origin': 'http://www.cninfo.com.cn', 'Referer': 'http://www.cninfo.com.cn/new/commonUrl?url=disclosure/list/notice', 'X-Requested-With': 'XMLHttpRequest' } headers['User-Agent'] = random.choice(User_Agent) # 定义User_Agent return headersxxxxxxxxxx# 深市年度报告def szse_annual_info(page, stock): query_path = 'http://www.cninfo.com.cn/new/hisAnnouncement/query' h = get_headers() query = {'stock': stock, 'tabName': 'fulltext', 'pageSize': 30, 'pageNum': page, 'column': 'szse', 'category': 'category_ndbg_szsh', 'plate': 'szse', 'seDate': '2012-07-01~2022-07-01', 'searchkey': '', 'secid': '', 'sortName': '', 'sortType': '', 'isHLtitle': 'true' }
namelist = requests.post(query_path, headers=h, data=query) return namelist.json()['announcements'] # json中的年度报告信息
# 沪市年度报告def sse_annual_info(page, stock): query_path = 'http://www.cninfo.com.cn/new/hisAnnouncement/query' # headers['User-Agent'] = random.choice(User_Agent) # 定义User_Agent h = get_headers() query = {'pageNum': page, 'pageSize': 30, 'column': 'szse', 'tabName': 'fulltext', 'plate': 'sse', 'stock': stock, 'searchkey': '', 'secid': '', 'category': 'category_ndbg_szsh', 'trade': '', 'seDate': '2012-07-01~2022-07-01', 'sortName': '', 'sortType': '', 'isHLtitle': 'true' }
namelist = requests.post(query_path, headers=h, data=query) return namelist.json()['announcements'] # json中的年度报告信息xxxxxxxxxxdef get_firm_info_dict(key_word): url = "http://www.cninfo.com.cn/new/information/topSearch/detailOfQuery" data = { 'keyWord': key_word, 'maxSecNum': 10, 'maxListNum': 5, } hd = { 'Host': 'www.cninfo.com.cn', 'Origin': 'http://www.cninfo.com.cn', 'Pragma': 'no-cache', 'Accept-Encoding': 'gzip,deflate', 'Connection': 'keep-alive', 'Content-Length': '70', 'User-Agent': 'Mozilla/5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 75.0.3770.100Safari / 537.36', 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8', 'Accept': 'application/json,text/plain,*/*', 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8', } r = requests.post(url, headers=hd, data=data) info = r.json()['keyBoardList'][0] return infoxxxxxxxxxxdef annualInfo2df(annual_info): '''将爬虫获取的年度报告中信息转成df''' download_url_prefix = 'http://static.cninfo.com.cn/' a = [] for i in annual_info: sec_name = i['secName'] sec_code = i['secCode'] title = i['announcementTitle'] adjunct_url = i['adjunctUrl'] if '摘要' in title or '英文版' in title: pass else: dic = {'sec_name':sec_name, 'sec_code':sec_code, 'title':title, 'pdf_download_url':download_url_prefix + adjunct_url} dict2df = pd.DataFrame([dic]) a.append(dict2df) return pd.concat(a)xxxxxxxxxxdef get_pdf_url(firm_info_dict): '''获取pdf的url链接''' org_id = firm_info_dict['orgId'] code = firm_info_dict['code'] plate = firm_info_dict['plate'] code_plus_orgid = code + ',' + org_id #爬虫headers中的'stock'需要同时填入stockcode和orgid,例如'600004,gssh0600004' if plate == 'szse': szse_ann_info = szse_annual_info(1, code_plus_orgid) return annualInfo2df(szse_ann_info) elif plate == 'sse': sse_ann_info = sse_annual_info(1, code_plus_orgid) return annualInfo2df(sse_ann_info)xxxxxxxxxxdef get_file_from_url(save_path, pdf_url): '''根据save_path和pdf_url进行pdf下载''' send_headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36", "Connection": "keep-alive", "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8", "Accept-Language": "zh-CN,zh;q=0.8"} req = requests.get(pdf_url, headers=send_headers) # 通过访问互联网得到文件内容 bytes_io = io.BytesIO(req.content) # 转换为字节流 with open(save_path, mode='wb') as f: try: f.write(bytes_io.getvalue()) print('%s,下载成功!' % (save_path)) time.sleep(1) # 休眠处理 except: print('%s,下载失败!' % (save_path)) return bytes_ioxxxxxxxxxxdef is_exist(path): '''目录是否存在''' return os.path.isdir(path)def ensure_exist(path): '''确保路径的存在,如果不存在就重新创建一个''' if not is_exist(path): os.makedirs(path)def get_files(path): '''获取目录下的文件名''' files = os.listdir(path) if '.ipynb_checkpoints' in files: files.remove('.ipynb_checkpoints') else: pass for file in files: if file.__contains__('.png'): #如果存在png文件也删掉 files.remove(file) return files
def get_dir_path(stock_name): '''获取保存路径名称''' base_dir = os.path.dirname(os.path.dirname(os.path.abspath('__file__'))) report_dir = os.path.join(base_dir, 'AnnualReport') #原路径加入AnnualReport文件夹 report_raw_dir = os.path.join(report_dir,stock_name) #AnnualReport文件夹中加入stock_name文件夹 return report_raw_dirxxxxxxxxxxdef spider_main(stock_code, stock_name): #创建文件夹 if '*' in stock_name: dirPath = get_dir_path(stock_name.strip('*')) else: dirPath = get_dir_path(stock_name) ensure_exist(dirPath) #判断有没有这个路径,没有的话会自动创建 #爬取公司基础信息并保存为字典 firmInfoDict = get_firm_info_dict(stock_code) #获取年报pdf下载链接并保存为dataframe firmAnnRepUrl = get_pdf_url(firmInfoDict)
#开始下载 for i in range(len(firmAnnRepUrl)): t = firmAnnRepUrl.title.values[i] if '*' in t: dirName = t.strip('*') + '.pdf' #有星号不能保存 else: dirName = t + '.pdf' pdfUrl = firmAnnRepUrl.pdf_download_url.values[i] savePath = os.path.join(dirPath, dirName) get_file_from_url(savePath, pdfUrl)xxxxxxxxxxfor stkName,stkCode in ind_stk_dict.items(): spider_main(stock_code=stkCode, stock_name = stkName) print('----------------------下一家----------------------')print('全部完成!!!')xxxxxxxxxxC:\Users\Felik\PythonFinalTest\AnnualReport\ST当代\2021年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\ST当代\2020年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\ST当代\2019年年度报告(更新后).pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\ST当代\2019年年度报告(已取消).pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\ST当代\2017年年度报告(更新后).pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\ST当代\2018年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\ST当代\2017年年度报告(已取消).pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\ST当代\2017年年度报告(已取消).pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\ST当代\2016年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\ST当代\2015年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\ST当代\2014年年度报告(更新后).pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\ST当代\2014年年度报告(已取消).pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\ST当代\2013年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\ST当代\2012年年度报告(更新后).pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\ST当代\2012年年度报告(已取消).pdf,下载成功!----------------------下一家----------------------C:\Users\Felik\PythonFinalTest\AnnualReport\视觉中国\2021年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\视觉中国\2020年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\视觉中国\2019年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\视觉中国\2018年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\视觉中国\2017年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\视觉中国\2016年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\视觉中国\2015年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\视觉中国\2014年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\视觉中国\2013年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\视觉中国\2012年年度报告.pdf,下载成功!----------------------下一家----------------------C:\Users\Felik\PythonFinalTest\AnnualReport\美盛文化\2021年年度报告全文.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\美盛文化\2021年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\美盛文化\2020年年度报告(更新后).pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\美盛文化\2020年年度报告(已取消).pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\美盛文化\2019年年度报告(更新后).pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\美盛文化\2019年年度报告(已取消).pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\美盛文化\2018年年度报告(更新后).pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\美盛文化\2018年年度报告(已取消).pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\美盛文化\2017年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\美盛文化\2016年年度报告(更新后).pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\美盛文化\2016年年度报告(已取消).pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\美盛文化\2015年年度报告(更新后).pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\美盛文化\2015年年度报告(已取消).pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\美盛文化\2014年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\美盛文化\2013年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\美盛文化\2012年年度报告.pdf,下载成功!----------------------下一家----------------------C:\Users\Felik\PythonFinalTest\AnnualReport\宋城演艺\2021年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\宋城演艺\2021年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\宋城演艺\2020年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\宋城演艺\2019年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\宋城演艺\2018年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\宋城演艺\2017年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\宋城演艺\2016年年度报告(更新后).pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\宋城演艺\2016年年度报告(已取消).pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\宋城演艺\2015年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\宋城演艺\2014年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\宋城演艺\2013年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\宋城演艺\2012年年度报告.pdf,下载成功!----------------------下一家----------------------C:\Users\Felik\PythonFinalTest\AnnualReport\芒果超媒\2021年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\芒果超媒\2020年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\芒果超媒\2019年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\芒果超媒\2018年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\芒果超媒\2017年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\芒果超媒\2016年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\芒果超媒\2015年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\芒果超媒\2014年年度报告(更新后).pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\芒果超媒\2014年年度报告(已取消).pdf,下载成功!----------------------下一家----------------------C:\Users\Felik\PythonFinalTest\AnnualReport\锋尚文化\2021年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\锋尚文化\2020年年度报告.pdf,下载成功!----------------------下一家----------------------C:\Users\Felik\PythonFinalTest\AnnualReport\祥源文化\2021年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\祥源文化\2020年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\祥源文化\2019年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\祥源文化\2018年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\祥源文化\2017年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\祥源文化\2016年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\祥源文化\2015年年度报告(修订版).pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\祥源文化\2015年年度报告(修订版).pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\祥源文化\2015年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\祥源文化\2014年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\祥源文化\2013年年度报告(修订版).pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\祥源文化\2013年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\祥源文化\2012年年度报告(修订版).pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\祥源文化\2012年年度报告.pdf,下载成功!----------------------下一家----------------------C:\Users\Felik\PythonFinalTest\AnnualReport\风语筑\上海风语筑文化科技股份有限公司2021年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\风语筑\上海风语筑文化科技股份有限公司2020年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\风语筑\2019年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\风语筑\2018年年度报告.pdf,下载成功!C:\Users\Felik\PythonFinalTest\AnnualReport\风语筑\2017年年度报告.pdf,下载成功!----------------------下一家----------------------全部完成!!!
xxxxxxxxxx#获取保存年报的AnnualReport文件夹的pathorigin_report_path = os.path.join(os.path.dirname(os.path.dirname(os.path.abspath('__file__'))),'AnnualReport')origin_report_path
xxxxxxxxxx'C:\\Users\\Felik\\PythonFinalTest\\AnnualReport'
xxxxxxxxxx# AnnualReport文件夹下的文件名stock_dir_name_list = os.listdir(origin_report_path)stock_dir_name_list
xxxxxxxxxx['ST当代', '宋城演艺', '祥源文化', '美盛文化', '芒果超媒', '视觉中国', '锋尚文化', '风语筑']
xxxxxxxxxxdef get_report_pdf_path_list(origin_report_path, stock_dir_name): '''获取年报pdf的路径list''' pdf_path_list = [] stock_dir_path = os.path.join(origin_report_path, stock_dir_name) print(stock_dir_path) files = get_files(stock_dir_path)# for d in os.listdir(stock_dir_path):# pdf_path_list.append(os.path.join(stock_dir_path, d))# if '.ipynb_checkpoints' in pdf_path_list:# pdf_path_list.remove('.ipynb_checkpoints')# else:# pass pdf_path_list = [os.path.join(stock_dir_path, x) for x in files] return pdf_path_listxxxxxxxxxx# tmp_report_pdf_path_list = get_report_pdf_path_list(origin_report_path, stock_dir_name_list[1])# tmp_report_pdf_path_listxxxxxxxxxxdef pdf2text(pdf_path): '''将pdf转成text''' tmp_pdf = pdfplumber.open(pdf_path) t = '' for i in range(len(tmp_pdf.pages)): t += tmp_pdf.pages[i].extract_text() return txxxxxxxxxxdef get_pdf_year(report_pdf_path): '''获取年报年份''' return re.findall(r'\d+',report_pdf_path)[0]xxxxxxxxxxdef get_eps_and_revenue(pdf_text): '''提取年报中的营业收入和eps值''' def get_value(re_obj, start_idx): data_line = re_obj.search(pdf_text[start_idx:]).group() #group:文本形式。提取出文本形式的 data_line = data_line.replace('\n', '') #有些年报格式不标准,数字有了换行,所以把换行符替换掉。 digit = re.compile(r'(-)?\d[,0-9]*?\.\d{1,2}') #匹配内容中的数字,获取所有','和0-9的数字,直到小数点后2位为止。 val = digit.search(data_line).group() #搜寻data_line中的digit内容 val = val.replace(',','') #把data里的逗号去掉 return val p_s = re.compile(r'(?<=\n)\w{1,2}、.*?会计数据和财务指标\s*?(?=\n)') #匹配标题 section_match = p_s.search(pdf_text) #抓取标题 s_idx = section_match.start() #定位标题 p = re.compile('营业收入(.*?)归属于',re.DOTALL) #匹配年报中的营业收入 k = re.compile('基本每股收益(.*?)稀释',re.DOTALL) #匹配年报中的基本每股收益 revenue = get_value(p, s_idx) earnings_per_share = get_value(k, s_idx) return revenue, earnings_per_sharexxxxxxxxxxdef get_address_and_web(pdf_text): '''提取年报中的办公地址和网址''' address_re = re.compile('(?<=\n)\w*办公地址:?\s?\n?(.*?)\s?(?=\n)',re.DOTALL) address = address_re.search(pdf_text).group().replace(',','') web_re = re.compile('https?://(?:[-\w.]|(?:%[\da-fA-F]{2}))+',re.DOTALL) web = web_re.search(pdf_text).group().replace(',','') return address, webxxxxxxxxxx#主运行模块total_stock_df_list = []for stock_dir_name in stock_dir_name_list: #在文件夹命名时未加星号,所以此时需要更正过来 if name == 'ST当代': name = '*ST当代' else: name = stock_dir_name for p_path in get_report_pdf_path_list(origin_report_path, stock_dir_name): single_stock_df_list = [] t = pdf2text(p_path) year = get_pdf_year(p_path) code = ind_stk_dict[name] print(year) revenue, eps = get_eps_and_revenue(t) try: address, web = get_address_and_web(t) except: print('网址识别失败!') dic = {'年份':year,\ '股票简称':name,\ '股票代码':code,\ '办公地址':address,\ '公司网址':web,\ '营业收入(元)':revenue, '基本每股收益(元/股)':eps } sub_df = pd.DataFrame([dic]) total_stock_df_list.append(sub_df)total_stock_df = pd.concat(total_stock_df_list)#解决办公地址一栏涵盖空格的问题total_stock_df['办公地址'] = total_stock_df['办公地址'].apply(lambda x: [x for x in x.split(' ') if x != ''][1])total_stock_dfxxxxxxxxxxC:\Users\Felik\PythonFinalTest\AnnualReport\ST当代2012201320142015201620172018201920202021C:\Users\Felik\PythonFinalTest\AnnualReport\宋城演艺2012201320142015201620172018201920202021C:\Users\Felik\PythonFinalTest\AnnualReport\祥源文化201220132014网址识别失败!20152016网址识别失败!2017网址识别失败!2018网址识别失败!2019网址识别失败!2020网址识别失败!2021网址识别失败!C:\Users\Felik\PythonFinalTest\AnnualReport\美盛文化2012网址识别失败!201320142015201620172018201920202021C:\Users\Felik\PythonFinalTest\AnnualReport\芒果超媒20142015201620172018201920202021C:\Users\Felik\PythonFinalTest\AnnualReport\视觉中国2012201320142015201620172018201920202021C:\Users\Felik\PythonFinalTest\AnnualReport\锋尚文化20202021C:\Users\Felik\PythonFinalTest\AnnualReport\风语筑2017网址识别失败!20182019网址识别失败!2020网址识别失败!2021
xxxxxxxxxx.dataframe tbody tr th {vertical-align: top;}.dataframe thead th {text-align: right;}
| 年份 | 股票简称 | 股票代码 | 办公地址 | 公司网址 | 营业收入(元) | 基本每股收益(元/股) | |
|---|---|---|---|---|---|---|---|
| 0 | 2012 | *ST当代 | 000673 | 山西省大同市魏都大道 | http://www.cninfo.com.cn | 16171025.34 | 0.01 |
| 0 | 2013 | *ST当代 | 000673 | 山西省大同市魏都大道 | http://www.lead-investment.com | 16792186.93 | 0.01 |
| 0 | 2014 | *ST当代 | 000673 | 山西省大同市魏都大道 | http://www.sz000673.com | 22400850.38 | -0.00 |
| 0 | 2015 | *ST当代 | 000673 | 北京市朝阳区光华东路5号世纪财富中心1号楼701室 | http://www.cninfo.com.cn | 492984466.50 | 0.36 |
| 0 | 2016 | *ST当代 | 000673 | 北京市朝阳区光华东路5号世纪财富中心1号楼701室 | http://www.cninfo.com.cn | 985528211.12 | 0.22 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 0 | 2017 | 风语筑 | 603466 | 北京市东城区青龙胡同1歌华大厦A座16层 | http://www.fssjart.com | 1499199025.12 | 1.46 |
| 0 | 2018 | 风语筑 | 603466 | 上海市静安区江场三路191、193号 | http://www.sse.com.cn | 1708361291.61 | 0.72 |
| 0 | 2019 | 风语筑 | 603466 | 上海市静安区江场三路191、193号 | http://www.sse.com.cn | 2029915182.15 | 0.91 |
| 0 | 2020 | 风语筑 | 603466 | 上海市静安区江场三路191、193号 | http://www.sse.com.cn | 2256301888.51 | 1.19 |
| 0 | 2021 | 风语筑 | 603466 | 上海市静安区江场三路191号 | http://www.sse.com.cn | 2939906282.47 | 1.20 |
65 rows × 7 columns
xxxxxxxxxx# total_stock_df.to_csv('最终结果.csv')xxxxxxxxxxresult = pd.read_csv('最终结果.csv',index_col=0)xxxxxxxxxxresult.dtypes
xxxxxxxxxx年份 int64股票简称 object股票代码 int64办公地址 object公司网址 object营业收入(元) float64基本每股收益(元/股) float64dtype: object
xxxxxxxxxxfrom matplotlib import pyplot as plt plt.rcParams["font.sans-serif"]=["SimHei"] #设置字体plt.rcParams["axes.unicode_minus"]=False #该语句解决图像中的“-”负号的乱码问题def plt_line(df, firm_name, target_col): '''绘制折线图''' year = df['年份'].tolist() val = df[target_col].tolist() max_year = max(year) min_year = min(year) plt.title(f'{firm_name}{min_year}-{max_year}间{target_col}走势图 ') plt.xlabel("年份") plt.ylabel(target_col) plt.plot(year,val) plt.show()xxxxxxxxxxfor fname in result['股票简称'].unique(): f_df = result.loc[result['股票简称'] == fname, :] plt_line(f_df, firm_name=fname, target_col='营业收入(元)')
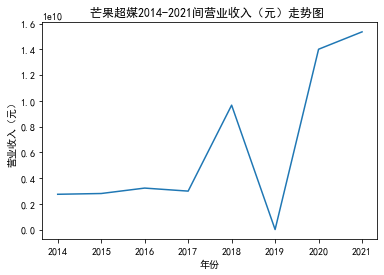
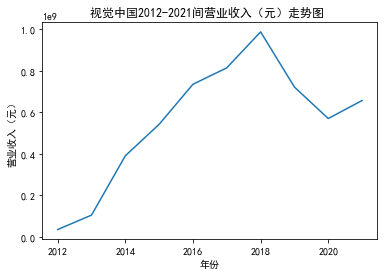
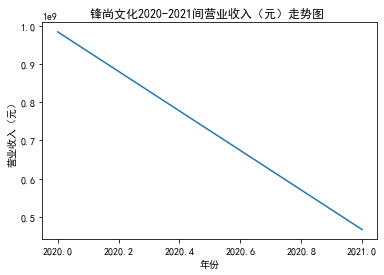
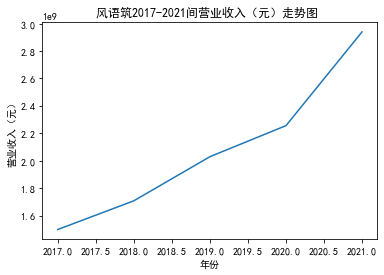
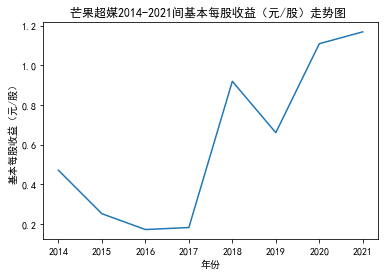
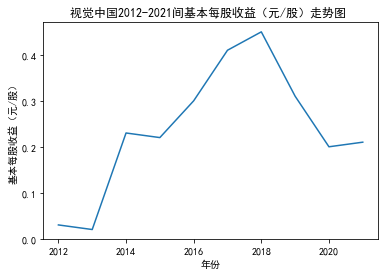
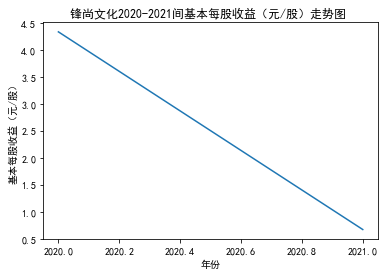
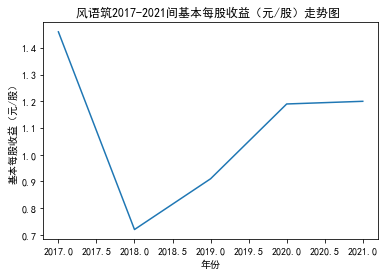
xxxxxxxxxxfor fname in result['股票简称'].unique(): f_df = result.loc[result['股票简称'] == fname, :] plt_line(f_df, firm_name=fname, target_col='基本每股收益(元/股)') 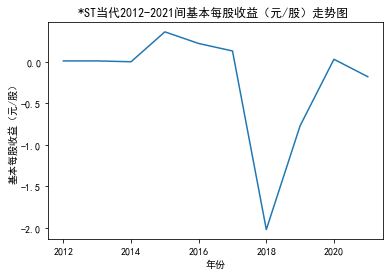
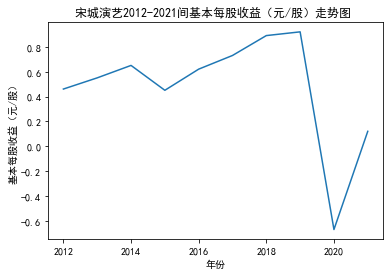
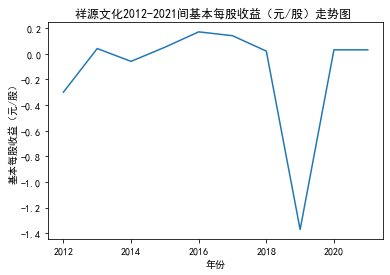
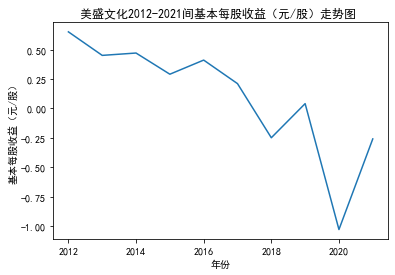
xxxxxxxxxxdef plt_bar(df, year, target_col): '''绘制柱状图''' x_name =list(df['股票简称']) y_val = df[target_col].tolist() plt.title(f'{year}年{target_col}对比图 ') plt.xlabel("股票简称") plt.ylabel(target_col) plt.bar(x_name,y_val) plt.xticks(rotation =30) plt.show()
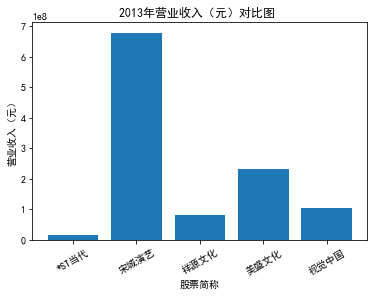
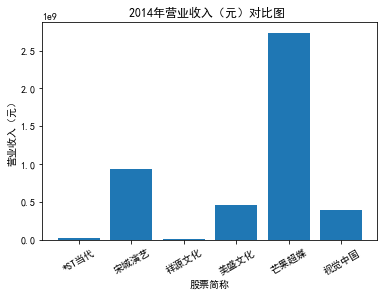
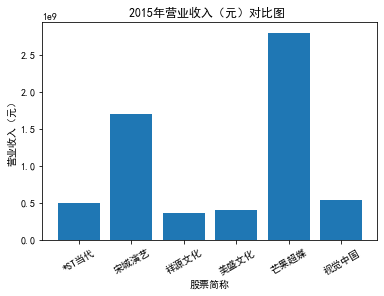
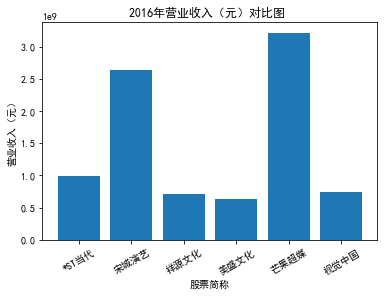
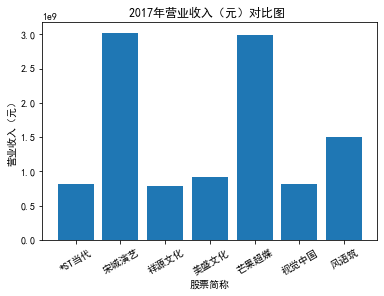
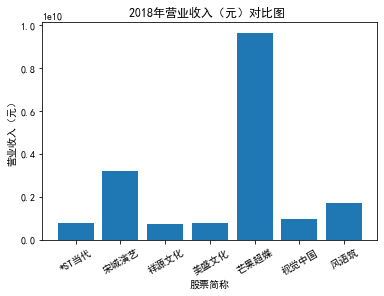
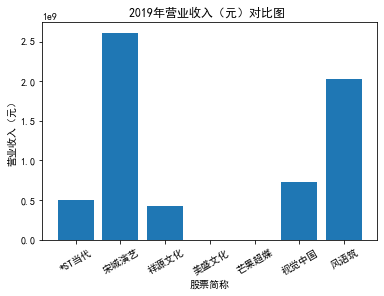
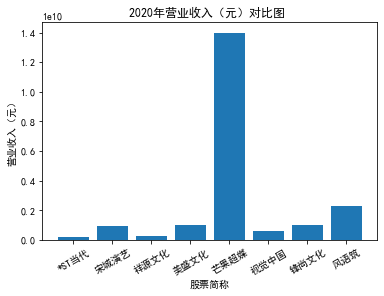
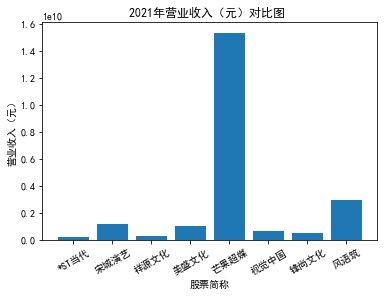
xxxxxxxxxxfor yr in sorted(result['年份'].unique()): yr_df = result.loc[result['年份']==yr, :] plt_bar(yr_df, year=yr, target_col='营业收入(元)')### 营业收入(分公司) 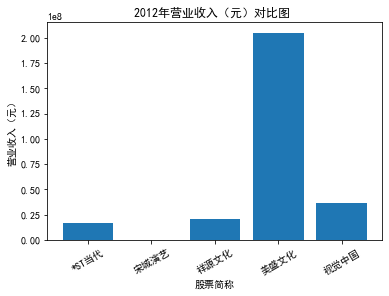
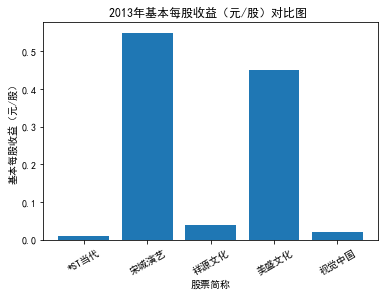
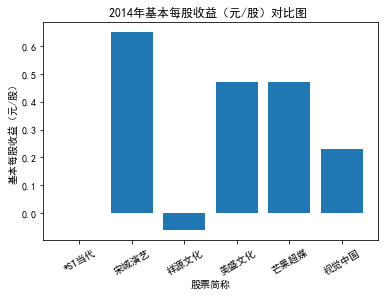
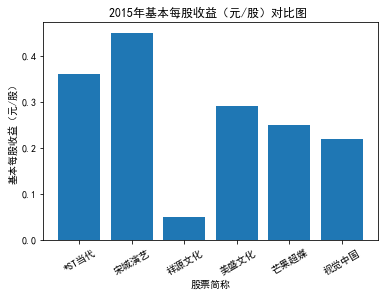
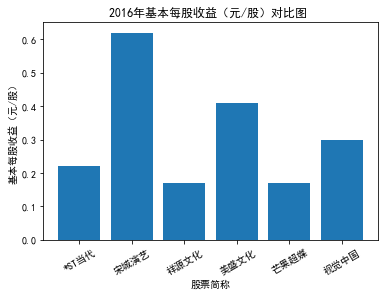
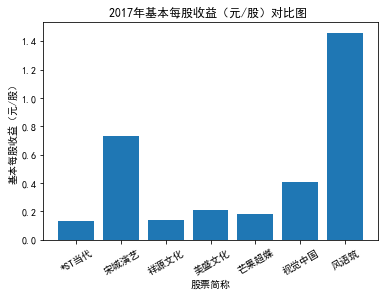
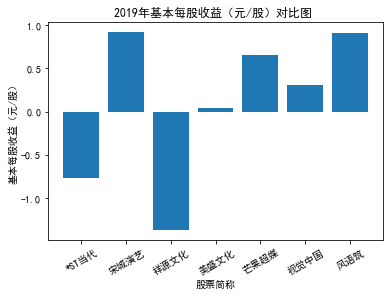
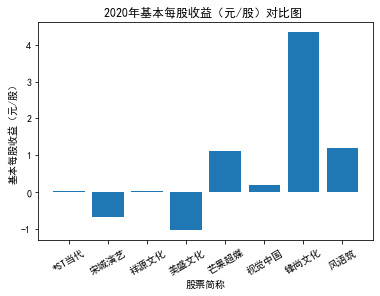
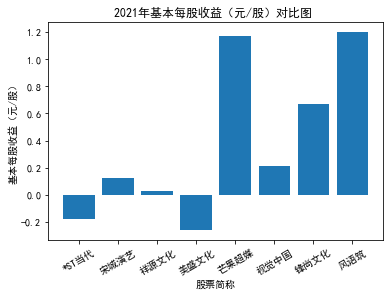
xxxxxxxxxxfor yr in sorted(result['年份'].unique()): yr_df = result.loc[result['年份']==yr, :] plt_bar(yr_df, year=yr, target_col='基本每股收益(元/股)')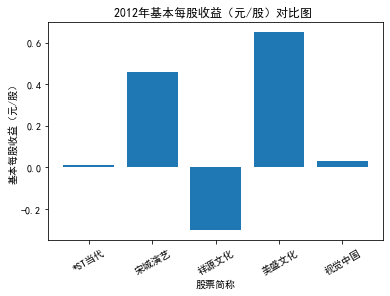
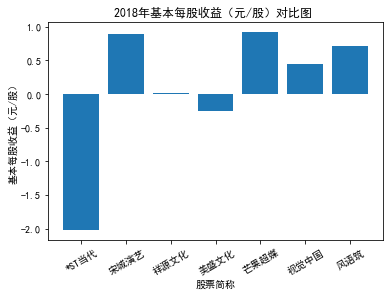
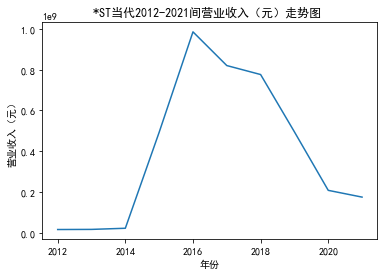
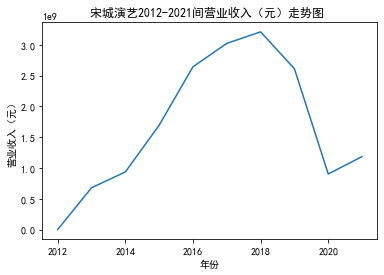
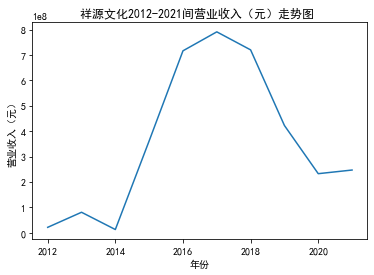
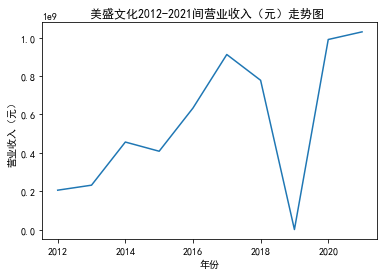
第一个解读角度从营业收入出发,横向对比不同的公司和纵向分析不同的年度。在2012-2021年间,文化艺术行业中的大多数公司在2018年前都处于稳步上升的过程,呈现向好趋势,而在2018年后,由于受到政策等因素的影响,均呈现出下滑态势,逐渐下降。纵向对比每家公司2012-2021年间的收入情况,宋城演艺在2019年之前收入都处于行业中的领先地位,而在2019年之后急剧下降。芒果超媒自2014年开始,一直是行业的龙头企业,逐渐取代了先前的巨头行业,潜力强劲,而与之相比,视觉中国、风语筑的行业份额逐年下降。
第二个解读角度侧重于对基本每股收益进行分析,同样分为横向对比及纵向对比。从年份来看,大多公司在2018年前都具有逐步上升的每股收益,而在2018年之后,基本收益都出现了波动或者小幅下降。再从纵向来分析每家公司的表现,宋城演艺和美盛文化在2016年之前的每股收益一直是行业中的最高值,高于0.5元/股,而在2016年之后,芒果超媒逐渐缩短了和宋城演艺、美盛文化基本每股收益的差距。2017年之后,风语筑的每股收益忽然上升,跻身进入行业领先水平。
从绘制的图像综合来看,大多数公司的营业收入和基本每股收益大致是一致的趋势,可以表示出该公司在行业中的地位、份额等,我们可以结合其他数据再进一步深入研究公司的运营情况。